Спиннер, вейп, свитшот: как Яндекс.Переводчик учит «хайповые» слова
Язык постоянно пополняется новыми словами. Одни остаются в лексиконе надолго, другие быстро забываются. Благодаря интернету освоение новых слов происходит стремительно: сначала неологизм появляется в речи блогеров, затем его подхватывают журналисты, телеведущие и чиновники. Очень скоро слово начинает звучать в эфире, мелькать в новостях и соцсетях, использоваться в переписке. Раз неологизм вошёл в язык, пусть даже ненадолго, Яндекс.Переводчик должен понимать, что он означает, — и уметь его правильно переводить.
Почему автоматическим переводчикам сложно быстро выучивать новые слова

Розеттский камень — самый известный пример параллельных текстов. Изображение с сайта Британского музея.
Многие системы автоматического перевода, включая наш Переводчик, обучаются с помощью параллельных текстов. Это тексты, одинаковые по содержанию, но написанные на разных языках. Совокупность таких текстов называют параллельным корпусом. Корпус регулярно пополняется: в него можно добавлять, например, книги, статьи, новости — все эти материалы часто выходят на разных языках.
В параллельных текстах встречаются неологизмы. Проблема в том, что обновление корпуса занимает много времени. Во-первых, тексты могут слегка различаться по смыслу. Перед добавлением в корпус их необходимо «выровнять»: найти соответствия между предложениями, фразами и отдельными словами. Во-вторых, после добавления новых текстов нужно заново подсчитать для всего корпуса коэффициенты вероятности переводов. Корпус — это огромный массив текстов, поэтому подсчёт идёт довольно долго.
Получается, что переводить новые слова система начинает лишь спустя месяцы после их появления. Для неологизмов, которые умирают так же быстро, как и рождаются, это недопустимо долгий срок.
Новые слова в поиске
Чтобы Переводчик быстрее реагировал на появление новых слов, мы начали использовать дополнительный источник данных — поиск. Услышав новое слово в теле- или радиоэфире или встретив в интернете, люди уточняют его значение в поиске. Слова, которые мало искали (или вообще не искали) раньше и стали много искать сейчас, — кандидаты на роль неологизмов.
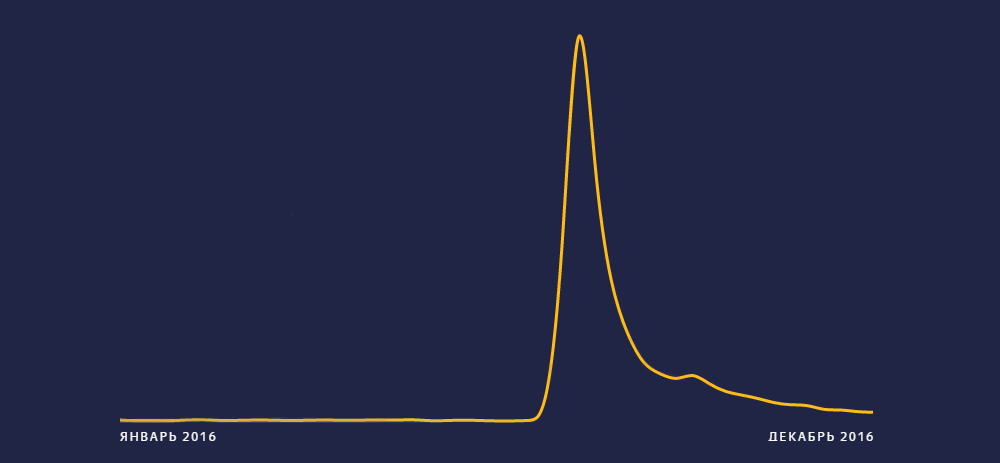
Что такое всплеск интереса и как его определить
Далеко не все кандидаты — действительно неологизмы. Всплеск интереса вызывают и премьеры фильмов, и герои новостей, и сезонные темы: на Пасху ищут куличи, а в преддверии Нового года спрашивают про ёлки. Чтобы отсеять лишнее, мы используем лингвистические фильтры: проверяем, является ли слово именованной сущностью и можно ли определить его грамматические признаки. Поскольку неологизмы часто ищут с целью узнать их значение, в запросах с ними нередко встречаются уточнения: [хайп что это значит], [блокчейн что это такое простыми словами]. Их тоже можно использовать как признак.
В результате фильтрации большая часть кандидатов в неологизмы отсеивается. Например, из 78 тысяч кандидатов, которых мы получили в первом полугодии 2017 года, после фильтрации осталась только тысяча.
Как получить перевод
Составить список вероятных неологизмов — лишь полдела. Необходимо научить Переводчик их правильно переводить. Около 85% новых слов — заимствования, в основном из английского языка. Обычно они получаются в результате записи кириллицей чего-то похожего на произношение иностранного слова. Запись при этом далеко не всегда соответствует нормативной транскрипции — как, например, в случае со словом «свитшот» [ˈswetʃɜːrt].
Яндекс.Переводчик может работать в двух режимах: переводчика и машинного словаря. Если вы введёте в поле фразу или текст, вы получите перевод, а если одно слово или устойчивое выражение — словарную статью. В машинном словаре накопилось много слов-заимствований и их готовых переводов. Мы создали модель, которая обучается на этих примерах и выдаёт несколько возможных вариантов перевода нового заимствованного слова. Например, для слова «свитшот» вероятными переводами будут «sweatshirt», «sweetshot», «sweetshirt».

Что такое CatBoost и как он работает
Вероятные переводы ранжирует классификатор на основе метода машинного обучения CatBoost. Он составляет список вариантов, где вверху находятся наиболее вероятные переводы, а внизу — наименее вероятные.
Словарная статья должна содержать не только перевод слова, но и грамматическую информацию, а также примеры использования. Здесь на помощь опять приходят данные из поиска. В поисковых запросах одно и то же слово, как правило, встречается в разных формах. Проанализировав их, можно выявить, к какой части речи оно принадлежит.
Примеры использования — это фразы из поисковых запросов. Они могут быть информативными и неинформативными. Скажем, к слову «хайповый» хорошим примером будет «хайповый шмот», а неудачным — «хайповый что это». Неудачные примеры отбрасывает автоматический фильтр.

Перевод неологизма, грамматические пометы и примеры использования составляют черновик словарной статьи. Она поступает на финальную проверку, которую проводят сотрудники Яндекса. После проверки слово добавляется в базу Переводчика. С этого момента сервис будет верно переводить неологизм в текстах и показывать для него словарную статью. Поскольку новые явления моментально находят отражение в поиске, Переводчик выучивает неологизмы очень быстро — спустя несколько дней после того, как о них начали спрашивать у Яндекса.
Короткий URL: https://nexusrus.com/?p=118678